

这篇文章的灵感来自于学生的问题,和许多人一样。看来我们中的许多人在分析中使用ROC曲线时,并不真正了解这些曲线的作用以及它们是如何产生的。
分类模型已经成为一种非常流行的工具,是许多已实施的广泛可用的黑盒解决方案的一部分,通常是作为机器学习工具的一部分。一方面,这种容易获得的即用型工具非常诱人,鼓励人们去尝试。另一方面,由于它是给定的,所以没有人寻求关于该方法的额外知识。很多时候,人们并没有看到这种分类模型的实施代码。因此,人们并不清楚这个黑盒子背后隐藏着什么。
让我们举一个医学的例子。让我们假设我们有一个二进制的0-1反应,表示一个病人是生病(1)还是健康(0)。此外,我们有一些关于病人的数据,我们认为或知道这些数据可能是患病或健康概率的潜在预测因素,如年龄、BMI、性别或吸烟。将我们的二元预测因子与预测因子的集合线性组合联系起来的模型称为逻辑回归模型。它是众所周知的线性正态回归模型的概括,但这次我们的反应是二进制的,而不是连续的,我们需要把这个二进制反应与模型的线性部分联系起来。这是通过所谓的链接函数发生的,它是Logistic回归模型的Logit函数。在R中,拟合逻辑回归模型的代码如下。
my_model<-glm(binary_response~ age + smoke + bmi + gender,family=binomial, data=my_data)
summary(my_model)上面的模型可能是在应用一些分片构建程序得到最终的一组重要预测因子后的最终模型。或者我们可能想在我们的数据上测试这些预测因子,因为我们从文献中知道它们在其他研究中已经被发现是显著的。
请注意,我们建立模型有两个原因。
- 对于推论来说,要推动结论的产生。然后,我们真的应该使用例如一些后向消除程序来消除那些不重要的预测者。
- 为了预测的目的。那么这个模型就会被过度拟合。只要它有良好的预测能力,我们并不太关心其中的内容。
让我们关注这第二个目的,因为这正是ROC曲线的用武之地。但首先要做的是。拟合模型后,我们想看看该模型的预测效果如何。理想情况下,我们应该在所谓的 "模型 "上建立/训练我们的模型。 训练集 然后在另一个人身上测试它 测试组.它可以是相同的数据,但我们只是用它的一部分作为训练部分,另一部分作为测试部分。所产生的问题是我们应该以何种比例来做。这不是一个小问题,而且是一个所谓的主题。 交叉验证 方法。理想情况下,我们应该检查不同的分割,并通过从我们的数据中随机抽样来重复这一程序。现在,让我们假设我们有用于建立模型的试验数据,而现在我们有新的数据,我们想检查我们模型的性能。
首先,我们从拟合的逻辑模型中创建对我们的反应的预测。
predicted<-predict(my_model,type=c("response"))重要的是要认识到,这将是一个预测的概率,而不是一个二元反应。比方说,对病人X的预测是0.7。这是否意味着他/她生病了?好吧,如果我们假设每个概率大于0.5的人都是病人,那么是的,根据我们的模型,他/她是病人。选择 阈值 0.5在这里是至关重要的。在我们选择了例如0.5之后,我们可以检查模型的性能。
predicted.threshold my_threshold)如果我们选择my_treshold为0.5,那么precited.treshold响应将是二进制的。对于那些概率大于0.5的情况,它将是1,否则是0。 然后我们可以看一下混淆矩阵。
table(my_data$binary_response,predicted.threshold)
预测.阈值
0 1
0 25 304
1 13 258从该混淆矩阵中,我们可以看到有多少 假阳性(FP) 我们的观察结果,也就是那些被模型预测为患病的人(1),但他们是健康的。此外,我们将有 假阴性 (FN) 观察,也就是那些被预测为健康的,但实际上是生病的。其余的观察结果将是 真阳性(TP), 预测正确的是生病和 真正的负数 (TN),预测正确为健康。
评估模型性能的常用措施是 灵敏度=TP/P,是指在所有患病的病人(P)中被检测出患病的比例。第二个衡量标准是所谓的 特异性=TN/N,这是所有健康病人中被检测出的健康比例。
现在,没有人告诉我们,我们的阈值必须是0.5。为什么不是0.6?如果我们改变阈值,预测结果就会改变,混淆矩阵就会改变,敏感性和特异性就会改变。
如何选择这个阈值以使特异性和敏感性最大化?我们的想法是让它们都很高。但是一旦敏感性提高,特异性就会下降,反之亦然。这是一个在这两者之间的权衡。
那么,我们是否需要为所有这些可能的阈值运行代码? 不,ROC曲线将为我们做这个。
library(pROC)
myROC<- roc(my_data$binary_response ~ predicted)
plot(myROC)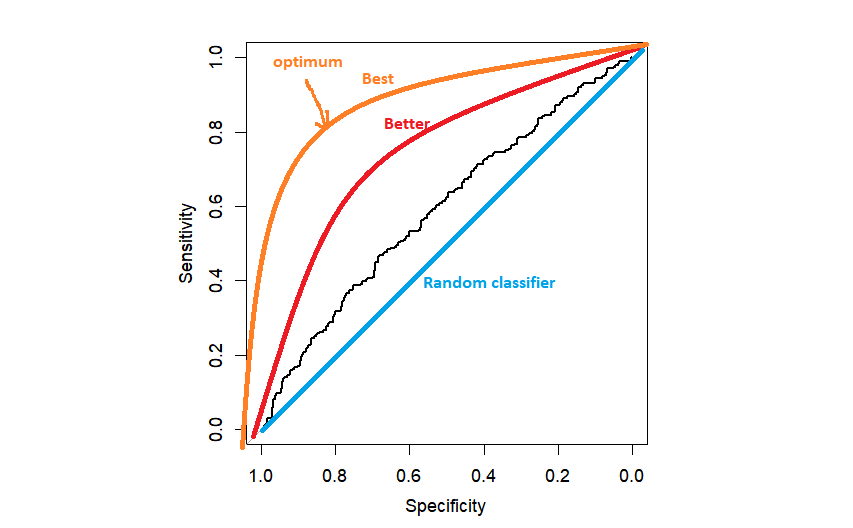
在实践中,我们可能会得到类似黑色ROC曲线的东西,只是比随机分类器好一点。ROC越接近左上角越好,因为我们越接近最大特异性=1和最大敏感性=1。
下一个问题是 如何选择门槛.最流行的方法是选择与左上角距离最大的阈值。它可以由R自动完成,但自己编程一次也不错。
topleft<-(1-myROC$sensitivities)^2+(1-myROC$specificities)^2
topleft.threshold<-which(topleft==min(topleft))
text(x=myROC$specificities[topleft.threshold], y=myROC$sensitivities[topleft.threshold], "(0.50,0.58)" ,col=2)一旦我们找到了这个最佳点,我们就可以用文本函数把它放在图上。在这一点上,人们通常会停下来,最后报告AUC(曲线下面积)作为模型的总预测能力。但是我们不应该在这里停止。我们要找出哪个阈值(截止点)对应于最佳的敏感性和特异性点。
#对于给定的敏感性和特异性
idx.which<-which((myROC$specificities=0.50)&(myROC$sensitivities=0.58)
1TP4现在我们采取阈值
myROC$thresholds[idx.which]。
predict.treshold myROC$thresholds[idx.which])
#混淆矩阵
table(my_data$binary_response,predict.threshold)现在我们已经找到了最佳阈值myROC$thresholds[idx.which],我们可以用它来削减我们的预测概率。
正如我之前提到的,ROC曲线下的面积通常被用来作为总结我们模型的整体预测能力的标准。我们应该意识到这是一种能力。 在所有可能的阈值中.越接近1就越好。随机分类器的AUC等于0.5,对应于上图中对角线下的面积。
当然,分类模型是比单纯的逻辑回归模型大得多的家族。这是一个广泛的研究课题。我们应该知道,除了 "左上角 "选择最佳标准外,还有其他方法,如Jouden标准。这个标准把敏感性和特异性看得同样重要。但情况并非总是如此。我们需要看一下手中的特定数据,因为 你的设置可能与别人的教程中的设置完全不同。 再来看看医学上的例子。如果你的疾病是癌症,你更担心的是假阴性观察,而不是假阳性。那些假阳性将被进一步诊断,但错过一些癌症患者可能会导致他们死亡。在这种情况下,你宁愿以特异性为代价来最大化灵敏度。另一方面,如果你的疾病是HIV,你可能对假阴性和假阳性病人都同样担心。
祝你的模特儿好运!
令人印象深刻的分享!我刚刚把这篇文章转发给了一位同事,他一直在做这方面的功课。
事实上,他给我订了晚餐,因为我发现
给他......笑。请允许我重新措辞:....
谢谢你的饭菜不过,谢谢你花时间在你的网站上讨论这个话题。
很高兴能帮上忙!